
Nachdem wir im zweiten Teil dieser Serie klären konnten, welche Voraussetzungen eine Datenarchitektur erfüllen muss, um sich das Prädikat zukunftssicher zu verdienen und die von Microsoft vorgeschlagene Best Practice-Plattform mit ersten jener Kriterien verglichen haben, wollen wir in diesem Teil prüfen, wo wir ganz eindeutig Verbesserungspotenziale identifiziert haben.
- Teil 1 – Oder: Was wollen wir eigentlich wissen und warum? 🤔
- Teil 2 – Oder: Die Datenplattform als eierlegende Wollmilchsau? 🐷
- Teil 3 – Oder: Welche Aufgaben erledigen Data Engineers und Data Analysts? 🔑
- Teil 4 – Oder: Wie entlaste ich mein Team mit nur einer Entscheidung? 💾
- Teil 5 – Oder: Welches Interface sollte es zu den Daten geben? 🕹 (wird noch veröffentlicht)
- Teil 6 – Oder: Sind alle meine Anforderungen erfüllt? Ein Fazit. 💡(wird noch veröffentlicht)
Vorweg noch: Ich durfte hierüber auch bereits auf der TDWI-Konferenz 2021 berichten – falls du also eher der visuelle Typ bist, schau dir meinen Vortrag hierzu bei YouTube an.
👀 Es geht immer besser…
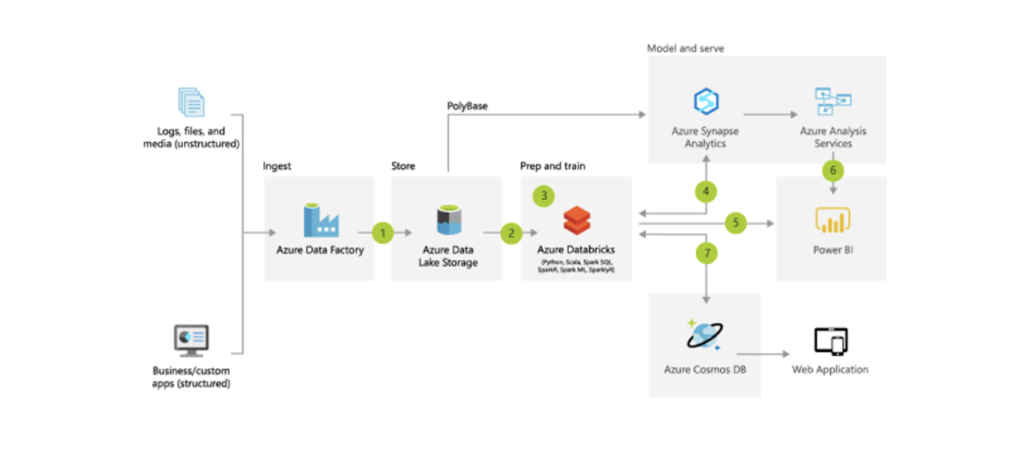
Wir konnten einige Eckpunkte bereits abhaken: So ist die von Microsoft selbst vorgeschlagene Architektur für die spezifischen Voraussetzungen (siehe Teil 1) von PAUL HEWITT hinsichtlich Wartbarkeit und Skalierung als auch Kosteneffizienz und Integrationsfähigkeit als durchaus praktikabel zu bewerten.
Ist die Infrastruktur auch einfach zugänglich? Hier kann ich mit einem sehr klaren Jein antworten. Meiner Einschätzung nach hängt die Beurteilung dieses Kriteriums stark davon ab, wen genau man fragt. Ich unterteile an dieser Stelle in zwei Stakeholder – Data Analysten und Data Engineers.
📊 Der Data Analyst
In vielen, wenn nicht den meisten Unternehmen ist der Data Analyst die Person, die sich mit den Fachabteilungen auseinandersetzt, deren analytische Anforderungen erhebt und idealerweise direkt umsetzt. Eines unser klar kommunizierten Projektziele war die Reduzierung der sog. time-to-insight: Wie viel Zeit vergeht zwischen Aufnahme der Anforderung und Bereitstellung des Ergebnisses an den Stakeholder? Wollen wir diese Spanne auf ein Minimum reduzieren, müssen wir dem Data Analyst sowohl die richtigen Werkzeuge an die Hand geben als auch fachlich dazu befähigen, seine Anforderungen eigenständig umsetzen zu können. Nur wie groß ist sein Einflussbereich in dieser Architektur tatsächlich?
Kenne die Stärken und Schwächen deiner Analysten
Ein ausgebildeter Data Analyst hat in der Regel – und so auch bei PAUL HEWITT – zwar zumeist gute bis sehr gute Kenntnisse in SQL (ein Glück haben wir Tobi 🙏), der lingua franca der Datenwelt, verfügt jedoch nur äußerst selten über eine klassische Ausbildung in Elementen der Softwareentwicklung. Seine Stärken liegt in der Kommunikation mit den Stakeholdern und seiner Übersetzungsfunktion zwischen Data & Business. Er nutzt seine Fachexpertise und analytischen Skills, um Zusammenhänge zu erkennen und diese adressatengerecht in aussagekräftigen Visualisierungen aufzubereiten.

Eine klassische Programmiersprache, wie z.B. Python oder DevOps-Kenntnisse (Git, CI/CD) hat er qua Ausbildung jedoch meist nicht – insbesondere bei kleineren Unternehmen, wo der Analyst häufig aus dem traditionellen Controlling kommt. Das ist insofern problematisch, als das ich persönlich die leidvolle Erfahrung gemacht habe, dass die wirklich (!) professionelle Arbeit mit Daten auch robuste, reproduzierbare und zugleich getestete Prozesse erfordert – also all das, was in der Softwareentwicklung bereits seit zehn Jahren zum Standardvokabular eines jeden anständigen Projekts gehört.
Niemand will dem CEO den Fehler erklären müssen, warum der Umsatz die vergangenen zwei Wochen doch 15 Prozent niedriger war. I promise. 🤞
Wenn der Data Analyst also nicht über diese Kenntnisse verfügt, ist er folglich darauf angewiesen, dass eine weitere Person mit ebendiesen Kenntnissen jene Daten für ihn in ein Schema bringt – sie also transformiert –, welches ihm wiederum zugänglich ist, z.B. via SQL oder BI-Tool. Der Data Analyst kann folglich in dieser Architektur seine eigenständig aufgenommenen Anforderung zumeist gar nicht selbstständig umsetzen und muss hierzu im Zweifel einen Data Engineer konsultieren. Die Herausforderungen, die hiermit einhergehen, liegen auf der Hand:
Die analytischen Anforderungen müssen nicht nur zwischen Stakeholder und Data Analyst kommuniziert werden, sondern auch zwischen Data Analyst und Data Engineer. Dies hat in unserer Konstellation so manches Mal zu Verständnisproblemen und folglich zu vermeidbarer Nacharbeit geführt. Außerdem ist es äußerst schwierig, die Auslastung zwischen Data Analyst und Engineer korrekt auszutarieren – häufig wartet einer an den anderen, die Arbeit lässt sich nicht immer gänzlich parallelisieren. Vor allem in kleinen Teams.
🔧 Der Data Engineer
Wie bewertet unser Data Engineer die Zugänglichkeit der Infrastruktur? Für einen gut ausgebildeten Data Engineer sind Daten in der Regel immer irgendwie zugänglich – unabhängig von der spezifischen Infrastruktur. Allerdings stellt sich hier die Frage: Wie und wofür will man ihn effektiv einsetzen?
Hast du schon mal einen Data Engineer als Stelle für dein Unternehmen suchen müssen? Falls ja, dann weißt du bestimmt, wie wertvoll und selten diese Ressource ist. Ich war seinerzeit in der glücklichen Lage einen hervorragenden Data Engineer finden und beschäftigen zu dürfen (Hi Dennis 👋), nur wie häufig leistet sich ein Neustarter auf diesem Gebiet tatsächlich eine derart gut situierte Stelle mit letztlich unklarem ROI? Eher nicht so oft.

Für einen Data Engineer gab es in diesem Projekt insbesondere die Herausforderung, recht viele unterschiedliche Marketing-Datenquellen und -APIs anzuzapfen – Google Analytics & AdWords, TikTok, Facebook Business Manager, AWIN, Criteo usw. usf. Microsoft stellt in seiner Best Practice-Architektur mit Azure Data Factory und Azure Functions grundsätzlich Möglichkeiten bereit, die Daten aus diesen Quellen zu extrahieren – allerdings ist hierzu stets die Entwicklung eines eigenen Konnektors zu der jeweiligen API notwendig. Die Authentifizierungsverfahren, Datenschemata und sonstige technische Voraussetzungen zwischen diesen Marketing-Datenquelle sind in der Regel doch recht unterschiedlich, so dass die Synergien in der Entwicklung dieser Konnektoren nur spärlich sind.
Und was passiert, wenn eine dieser Plattformen auf die fixe Idee kommt, Änderungen an seiner API vorzunehmen? Insbesondere die Wartung und kontinuierliche Weiterentwicklung der Konnektoren kann langfristig zu einem echten Ressourcenproblem werden. Alleine für die initiale Entwicklung haben wir intern etwa sechs Monate geschätzt.
Das Kriterium der Zugänglichkeit der Entscheidungsplattform lässt sich für diese beiden Stakeholder folglich als ausbaufähig konstatieren.
🪄 Sind die Komponenten der Architektur denn wenigstens flexibel austauschbar, gar open source?
Viele Unternehmen nutzen heute bereits Komponenten verschiedener Cloud-Provider – AWS, Azure oder Google –, sogenannte Multicloud-Setups. Und ja, das funktioniert. Meiner persönlichen Einschätzung nach kann man jedoch feststellen, dass sich die Anbieter aus nachvollziehbaren Gründen durchaus Mühe geben, ihre eigenen Dienste stets zu bevorzugen, insbesondere in dem sie sich häufig leichter als die Konkurrenzprodukte integrieren lassen. Es sind gated communities mit einem gewissen Maß an Durchlässigkeit.
Zudem sind diese Komponenten in der Regel closed-source. Eigene Anpassungen und Erweiterungen sind nicht ohne Weiteres möglich. Dienste können zudem potenziell von heute auf morgen abgestellt oder zumindest funktional eingeschränkt werden. Auch sind die Datenformate oftmals proprietär. Datensets haben nur leider die Angewohnheit, dass es immer schwieriger wird, sie zu einem anderen Anbieter oder in eine andere Technologie zu transferieren, je größer sie werden – man sagt, dass sie eine gewisse Schwerkraft entwickeln.
Eine Plattform, sie zu knechten, sie alle zu integrieren,
Ins Dunkel zu treiben und ewig zu binden
Ist man folglich erstmal in Azure Synapse Analytics eingekauft, geht man aus finanziellen wie technischen Gründen nicht mehr so schnell wieder dort weg. Bitte nicht falsch verstehen: Synapse Analytics ist durchaus ein leistungsfähiges und konkurrenzfähiges Produkt. Nur ist die Innovationskraft in dieser Branche momentan so außerordentlich, dass beinahe täglich neue Werkzeuge entstehen – wer will sich jetzt schon auf einen Anbieter committen?
Abschließend können wir also zusammenfassen, dass wir mit dieser cloud-nativen Infrastruktur und ausschließlicher Nutzung von Microsoft-Komponenten und Azure Databricks nicht allzu viel falsch machen – es ist leicht zu administrieren, durchaus kosteneffizient, lässt sich in unserem Projekt hervorragend integrieren und skaliert auf Knopfdruck.
Allerdings konnten wir auch Verbesserungspotenziale identifizieren. Die gefühlte Wahrheit nach Abschluss einer umfangreichen Proof-Of-Concept-Phase war, dass uns die kritische Kenngröße time-to-insight weiterhin zu hoch war. Wir wollten mehr.
Daher haben wir uns gefragt:
- Wie schaffen wir es, dass der Data Analyst beinahe autark seine erhobenen Anforderung selbstständig umsetzen kann?
- Wie befreien wir den Data Engineer von der Last, neue Konnektoren zu Datenquelle zu entwicklen und warten zu müssen?
- Wie können wir die Infrastruktur flexibel gestalten, um auch auf zukünftige Herausforderungen und Marktanpassungen adäquat reagieren zu können?
Dazu mehr im vierten Teil dieser Artikelserie.



