
Im ersten Teil dieser Serie habe ich dargestellt, welche Voraussetzungen und Hintergründe dazu geführt haben, die Einführung einer zukunftssicheren Entscheidungsplattform zu evaluieren. Insbesondere haben wir bei PAUL HEWITT identifiziert, dass wir bisher noch zu wenig über unsere Kunden wissen – wer sie sind, woher sie kommen und was sie letztlich zum Kauf oder Nicht-Kauf bewegt.
Wir haben folglich das Ziel ausgegeben, diese Fragen standardisiert, automatisiert und für jede:n zugänglich zu beantworten. Da wir bereits festgestellt hatten, dass unser bisheriger Werkzeugkasten – Tableau und Tableau Prep – für diese Zielsetzung kaum ausreichend war, haben wir zunächst skizziert, welche Anforderungen wir intern an eine zukunftssichere Dateninfrastruktur stellen und sind dann in die Marktrecherche gegangen.
- Teil 1 – Oder: Was wollen wir eigentlich wissen und warum? 🤔
- Teil 2 – Oder: Die Datenplattform als eierlegende Wollmilchsau? 🐷
- Teil 3 – Oder: Welche Aufgaben erledigen Data Engineers und Data Analysts? 🔑
- Teil 4 – Oder: Wie entlaste ich mein Team mit nur einer Entscheidung? 💾
- Teil 5 – Oder: Welches Interface sollte es zu den Daten geben? 🕹 (wird noch veröffentlicht)
- Teil 6 – Oder: Sind alle meine Anforderungen erfüllt? Ein Fazit. 💡(wird noch veröffentlicht)
Vorweg noch: Ich durfte hierüber auch bereits auf der TDWI-Konferenz 2021 berichten – falls du also eher der visuelle Typ bist, schau dir meinen Vortrag hierzu bei YouTube an.
Die eierlegende Wollmilchsau finden
Die Entscheidungsplattform sollte natürlich idealerweise…
- manageable ⚙️ sein, also möglichst einfach wartbar und administrierbar: Zugänge und Rechte für die Mitarbeiter sollen einfach zu konfigurieren sein, Funktions- und Sicherheitsupdates möglichst automatisiert ohne spezielles Zutun interner Ressourcen stattfinden und neue Ressourcen und Funktionalitäten sollen sich schnell und einfach bereitstellen lassen. Dabei muss diese Infrastruktur gleichzeitig höchsten Sicherheitsstandards genügen.
- skalierbar 🚀 sein, also mit dem Unternehmen und seinen analytischen Anforderungen mitwachsen. Bei dem dynamischen Wachstum des Unternehmens zu dieser Zeit war es kaum zu prognostizieren, welche Hausforderungen in einem Jahr – geschweige denn in drei Jahren – zu meistern sein werden. Produkttrends ändern sich schnell und in wenigen Monaten entstehen neue, hochrelevante Marketingkanäle (Hallo TikTok! 👋). Auch die Anzahl der Mitarbeiter wuchs kontinuierlich und so auch ihr Hunger nach Daten – die Zugriffe auf Datenquellen häuften sich und machten die bestehende Infrastruktur zusehends zum Flaschenhals der Entscheidungsfindung.
- kostengünstig 💸 sein. Geld ist immer knapp, insbesondere für Projekte mit unbekanntem Return On Invest – oder sollte ich sagen Insight? Selbstverständlich müssen die aus den Daten gewonnenen Erkenntnisse die Entscheidungsfindung positiv beeinflussen, so dass bessere Entscheidungen schlussendlich auch zu mehr Profit führen.
- integrierbar 🔐 sein, sich also in das vorhandene Ökosystem und die Arbeitsprozesse des Unternehmens einfügen und keine zusätzliche Komplexität aufladen. Wie einfach kann ich meine Insights mit anderen teilen? Wie komplex ist der Anmeldeprozess zur Plattform? Wie einfach lassen sich neue und bestehende Tools miteinander verzahnen?
- zugänglich 💻 sein. Meiner Erfahrung nach bindet der Endanwender Daten in seine Entscheidungsfindung erst dann ein, wenn diese leicht konsumierbar und einfach zugänglich sind. Sind die Hürden zu groß, Daten für ein spezifisches Problem zu finden oder lassen sich die Daten nicht intuitiv und schnell analysieren, dann erfolgt die Entscheidung weiterhin aus dem Bauch heraus.
- flexibel 🧩 sein. Im Falle einer veränderten Erwartungshaltung an einzelne Bestandteile meiner BI-Infrastruktur möchte ich gezielt reagieren können, ohne gleich die ganze Infrastruktur über den Haufen werfen zu müssen. Modularität ist ohnehin eine Megatrend der Softwareindustrie: Moderne Software löst ein spezifisches Problem sehr gut („best-of-breed„) und nicht viele eher so mittelmäßig („best-of-suite„). Zudem habe ich persönlich eine große Präferenz für open source-Projekte, so dass ich im Zweifel bei ähnlichem Funktionsversprechen eher auf die freie Alternative setze.
Time-To-Insight als Erfolgsmaßstab

Die maßgebliche Kennzahl zur Bewertung des Projektserfolgs ist die time-to-insight. Wie viel Zeit wird benötigt, um aus einer vagen analytischen Anforderung ein echtes Data Asset zu produzieren – ein Dashboard, eine Visualisierung oder eine Recommendation Engine.
Mit diesen Zielen sind wir dann in die Marktrecherche gegangen. Wir nutzten bereits Microsoft Dynamics NAV als ERP-System und gleichzeitig auch die gesamte Microsoft Office-Suite, insbesondere Teams als internes Kollaborationswerkzeug. Somit hatten wir bereits einen gewissen Vendor Lock-in bei Microsoft und haben uns folglich zunächst auch das Angebot in Azure angeschaut, in der Hoffnung, gewisse Integrationsvorteile zu generieren. Und nach erster Begutachtung wurde offensichtlich, dass Microsoft hier gut aufgestellt ist und selbst eine Best Practice-Analysearchitektur für unsere Anforderungen vorschlug, die in etwa so aussah:
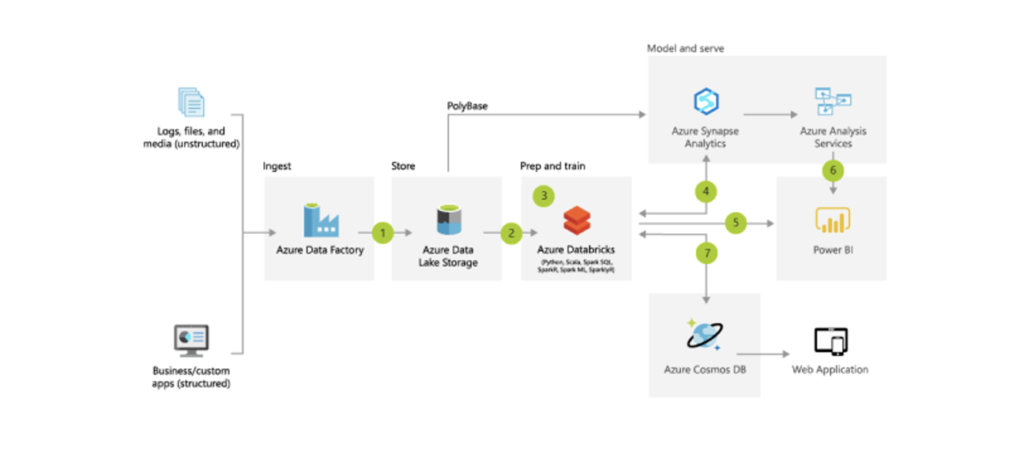
Was wir hier sehen, ist letztlich ein klassischer ELT-Prozess: Zunächst werden die Rohdaten aus den jeweiligen Datenbanken und APIs extrahiert (Azure Data Factory), um diese sodann unmittelbar in einem Data Lake zu sichern (Azure Data Lake Storage). Die Rechenleistung zur Transformation der Daten – also zur Reinigung, Aufbereitung und Anreicherung der Rohdaten um Geschäftslogik – übernimmt in diesem Architektur-Blueprint wiederum Azure Databricks, welches die transformierten Daten direkt in das Data Warehouse sichert (Azure Synapse Analytics). Power BI dient als Zugriffspunkt, um mit den Daten interagieren und diese in Charts und Dashboards aufbereiten zu können. Azure Analysis Services lasse ich hier bewusst aus. Viele Funktionen sind ohnehin nativ in Power BI integriert, so dass der Einsatz nur in speziellen Konfigurationen notwendig wird. Mehr dazu hier.
Vertrauen ist gut, Proof-Of-Concept ist besser
Wenn Microsoft dies schon als Best Practice betitelt, wollten auch wir uns daran orientieren und haben folglich einen Proof-Of-Concept erstellt, um diese Infrastruktur mit unseren Zielen zu vergleichen.

Ist diese Infrastruktur einfach wartbar und administrierbar? Wie ist die Integration in das bestehende IT-Umfeld zu bewerten?
Ein klares Ja. Letztlich ist dies Cloudtechnologie. Wenn die Cloud eines verspricht, dann sicherlich die einfache Konfiguration und schnelle Bereitstellung der abgebildeten Ressourcen. Microsoft selbst versorgt die Komponenten ständig mit Sicherheits- wie auch Funktionsupdates, beinahe wöchentlich gibt es neue Möglichkeiten und Erweiterungen. Ein dedizierter Datenbankadministrator ist für die Verwaltung dieser Infrastruktur nicht unbedingt notwendig, wenngleich natürlich ein gewisses Wissen um die Funktionsweise der Cloud und seiner Komponenten vorteilhaft ist. Die Dokumentation von Microsoft ist allerdings wie immer sehr vorbildlich, neuerdings werden gar ganze Lernpfade für die einzelnen Technologien einfach verständlich und interaktiv zur Verfügung gestellt – siehe hier. Auch integriert sich die Plattform in die bestehenden Unternehmenswerkzeuge für Zugangs- und Rechteverwaltung wie etwa Active Directory. Daumen hoch, Anforderungen erfüllt. ✅
Lässt sich diese Infrastruktur skalieren?
Ganz eindeutig ja. Auch hier gilt: Das ist Cloudtechnologie. Mit wenigen Klicks lässt sich die Leistungsfähigkeit der Infrastruktur erhöhen, bei moderatem Zuwachs der Kosten – meist sogar gänzlich ohne Unterbrechung des Funktionsfähigkeit an sich, so dass der Endanwender hiervon Nichts mitbekommt. Somit kann die Umgebung mit dem Unternehmen mitwachsen: Ich nutze (und zahle) nur das, was ich auch tatsächlich brauche. Das ist nicht nur nachhaltig, sondern auch kosteneffizient. ✅
Ist die Infrastruktur kostengünstig?
Darüber lässt sich natürlich streiten, da diese Beurteilung sehr individuell ist. Unsere Messgröße ist der time-to-insight. Und wenngleich diese nicht zu 100% quantifizierbar ist, war die subjektive Beurteilung im Proof-Of-Concept bereits sehr positiv. Nicht nur die einfache Administration hat Kosten gespart – ein dedizierter DBA ist einfach nicht mehr notwendig –, auch die Vermeidung von initialen Anschaffungskosten ist vorteilhaft: Durch das nutzungsbasierte pay-as-you-go-Abrechnungsmodell lassen sich die Kosten im Vorfeld bereits recht klar kalkulieren, dennoch empfehle ich gerade zu Beginn ein enges Monitoring, um ein Gefühl dafür zu entwickeln, wo die Kostentreiber der Architektur versteckt sind – in unserem Falle ganz eindeutig die Rechenleistung zur Transformation der Daten mittels Azure Databricks. Für mich also ebenfalls ein ja. ✅
Auf den ersten Blick sieht das bereits sehr vielversprechend aus. Warum wir allerdings bei der Beurteilung der Zugänglichkeit der Daten sowie der Flexibilität der Architektur Abstriche machen müssen, erfahrt ihr im nächsten Teil dieser Serie – in der nächsten Woche.



