"Die Datenwelt in der Chemie ist meist unstrukturiert, wenig standardisiert und daher digital aufwendig zu bearbeiten. chembid's Kernkompetenz sind Technologien und Werkzeuge, um Daten zu chemischen Produkten für digitale Dienste nutzbar zu machen. Die chembid Suchmaschine ist so ein Dienst."

Stefan Schweikart
CEO
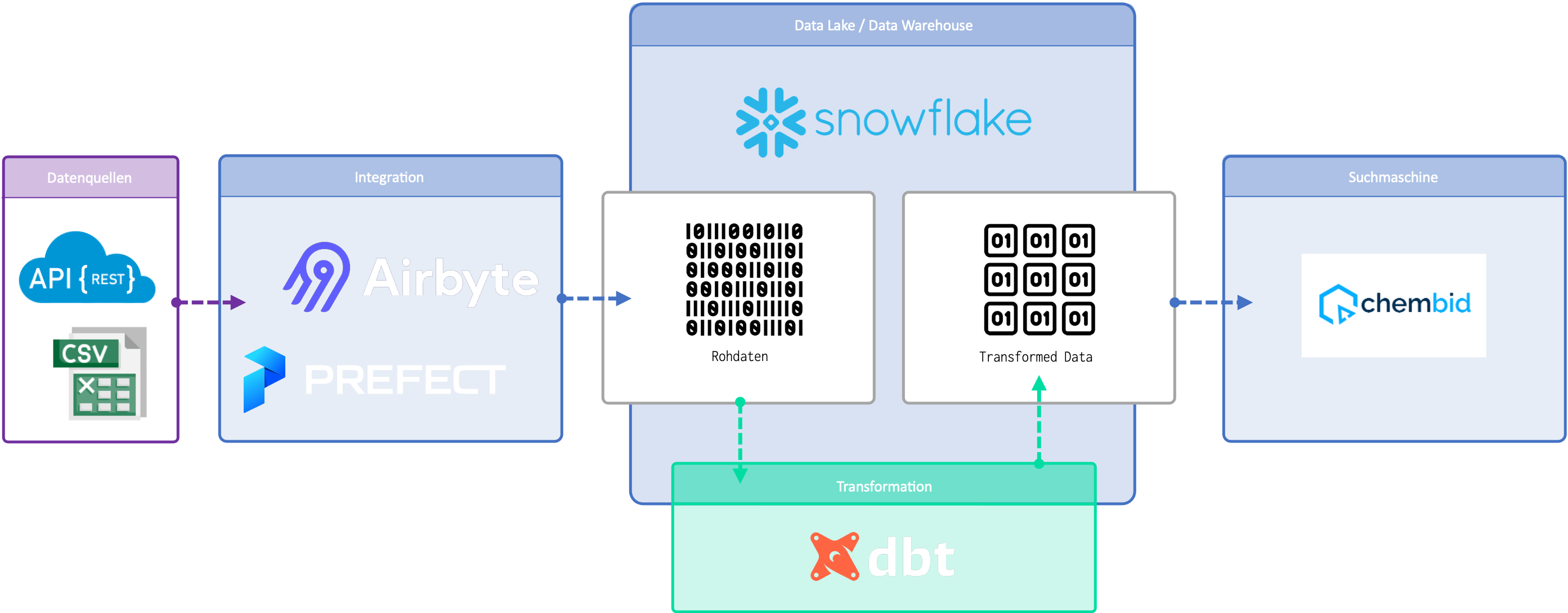
sikwel hat durch agiles Vorgehen, individuelle Schulung und äußerst professionelle Implementierung chembid einen “Jumpstart” in der Automatisierung von Datenpipelines ermöglicht. Erst dadurch war es so schnell möglich, eine produktive Basis für die skalierbare Entwicklung von ETL-Strecken zu legen.

Achim Mahnke
CTO
