
🎯 The reason why – 
In der Vergangenheit gab es in klassischen Data-Teams zwei Rollen: Data Analysts & Data Engineers. Data Analysts waren in erster Linie dafür zuständig, große Mengen von Daten zu analysieren und aus ihnen wichtige Erkenntnisse und Einsichten zu gewinnen. Sie verwenden verschiedene Tools und Techniken, um die Daten zu visualisieren und Muster und Trends zu erkennen, die für das Unternehmen von Bedeutung sein können („Auf welche Produkte sollte ich den Fokus legen?“, „Wohin sollte mein Marketingbudget fließen?“). Data Engineers hingegen arbeiteten eher im Verborgenen: Bei ihnen ging es darum, Data-Pipelines von der Quelle bis zum Report aufzubauen und Datenmodelle zu erstellen, durch deren Hilfe Data Analysts wiederum in der Lage waren, benötigte Dashboards zu visualisieren.
Nun besitzen beide Rollen unterschiedliche Stärken und Schwächen: Data Engineers sind Experten darin, Datenquellen miteinander zu verknüpfen und in der Lage, mit Hilfe ihrer Programmierfähigkeiten (z.B. Python) vormals ungeordnete Rohdaten in geordnete Strukturen zu verwandeln. Data Analysts kommen eher aus der analytischen Richtung: Sie sind stark darin, Herausforderungen aus dem Business in die Welt von Daten zu übersetzen und mit Hilfe ihrer analytischen Skills Lösungen in Dashboards und Analysen zu entwickeln. Kenntnisse klassischer Programmiersprachen? Eher selten. Bedeutet, dass Data Analysts stets darauf angewiesen waren, dass Data Engineers die initial ungeordneten Rohdaten in eine für spätere Analysen verwertbare Form transformieren.
Wer schon einmal stille Post gespielt hat weiß: je mehr Personen beteiligt, desto ungewisser das Ergebnis. Gleiches gilt, wenn (businessferne) Data Engineers die Aufgabe bekommen, Daten so zu transformieren, dass damit genau die Businessprobleme gelöst werden können, die vorab identifiziert wurden. Um dieses Gap zu schließen, gewann in den vergangenen Jahren die Position des Analytics Engineers an Bedeutung. Mit Hilfe moderner Tools wie dbt gelingt es diesem Personenkreis heute, auch ohne mehrjähriges Informatikstudium eigene Transformationen zu erstellen und so genau zum beabsichtigten Ergebnis zu kommen. Aber wie?
💡 First things first – about
Die Abkürzung dbt steht für „data build tool“ und erklärt somit schon den Zweck des Tools. dbt ist für den „T-Step“ in der ETL-Strecke verantwortlich. Wobei das eigentlich falsch ist, denn mit dbt rutscht das „T“, also der Schritt der Datentransformation ans Ende der ursprünglichen ETL-Strecke. Wir sprechen fortan nunmehr von ELT. (s. Abbildung 1).
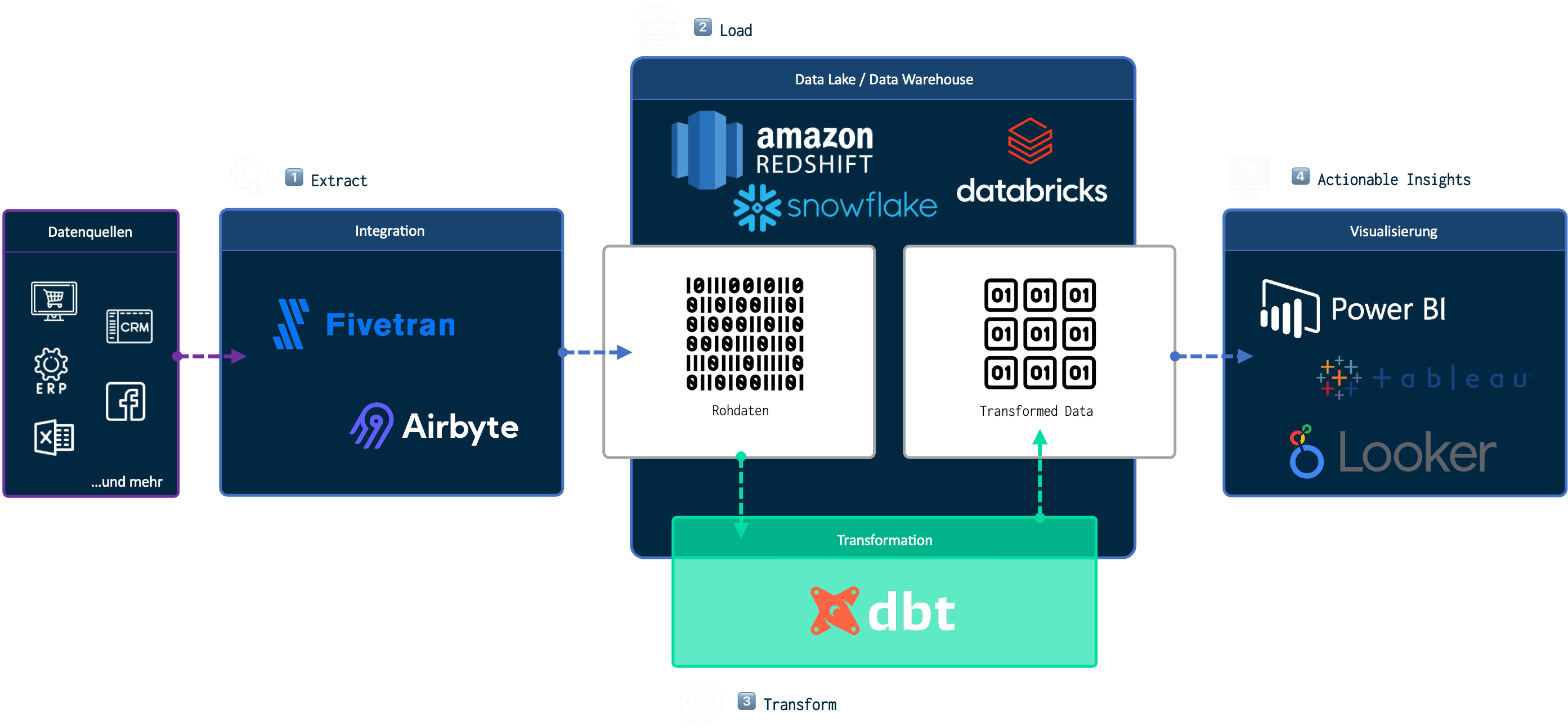 Abbildung 1: beispielhafte Dateninfrastruktur mit dbt
Abbildung 1: beispielhafte Dateninfrastruktur mit dbt
An den grundsätzlichen Funktionen der Arbeitsschritte innerhalb der ETL-Strecke ändert dies jedoch nichts.
- 1. Extract: Aus den Primärquellen wie z.B. Microsoft Dynamics, Hubspot oder Google Analytics werden die Daten extrahiert.
- 2. Load: Die extrahierten Daten aus den Primärquellen werden an einem Ort zentriert, in diesem Fall unser Data Warehouse.
- 3.Transform: Die ins Data Warehouse geladenen (bis dato ungeordneten) Rohdaten können nun (z.B. mit dbt) transformiert werden.
Die transformierten Daten können anschließend von BI-Tools wie PowerBI oder Tableau abgerufen und visualisiert werden. Bedeutet, dass die grundsätzliche Funktion von dbt darin besteht, vormals ungeordnete Rohdaten in geordnete und getestete Strukturen zu transformieren. Mit dem Ziel, dass alle initial aufgenommenen Anforderungen und Unternehmensspezifika in den finalen Reports abgedeckt werden können – von KPI-Definitionen über individuelle Absatzkanalstrukturen bis zur Zusammenführung von Tabellen aus den unterschiedlichsten Datenquellen.
🚀 The special thing about

Mit Hilfe von dbt können Data Analysts Analytics Engineers also fortan mit Hilfe simpler SQL-Statements eigene Transformationen erstellen – auch ohne die Hilfe von Data Engineers. Doch Datentransformation mit dbt steht der klassischen Programmierung in nichts nach: Nach Best Practice angewendet, lassen sich sowohl Staging- als auch Prod-Area im Data Warehouse umsetzen. Alle Analytics Engineers können in ihrem eigenen Datenbankschema arbeiten und ihre Anpassungen einem Remote-Repository wie z.B. github hinzufügen. Zudem lassen sich mit dbt-packages vordefinierte Modelle und Macros installieren, analog zu libraries in der klassischen Entwicklung. Es handelt sich bei dbt also nicht um einen einfach SQL-Abfrageeditor, sondern um eine Umgebung die alle wichtigen Funktionen der klassischen Programmierung ermöglicht – ohne programmieren zu müssen. Klingt gut, oder?
🙏 ![]()
dbt spielt also eine entscheidende Rolle auf dem Weg zur Demokratisierung von Daten. Dadurch, dass durch dbt die technische Einstiegshürde zur Transformation von Daten auf ein Minimum reduziert ist, können weit mehr Personen an Projekten mitwirken, wodurch es Unternehmen gelingt, dem Kampf um die rare (+ kostspielige) Ressource des Data Engineers zu entgehen. Somit wird es möglich, einerseits mehr Geschwindigkeit in die Umsetzung von Dateninitiativen zu bekommen als in klassischer Rollenverteilung und andererseits weit weniger Budget dafür aufzuwenden. Auch die Erfolgswahrscheinlichkeit für die Akzeptanz von Berichten wird um ein Vielfaches erhöht, da Anforderungsaufnahme und Realisierung dank dbt fortan bei der gleichen Person liegen können und die Risiken der stillen Post somit der Vergangenheit angehören.
Zudem wird durch die Automatisierung infrastruktureller Entwicklungsthemen einerseits wertvolle Zeit gespart, die viel besser in die Entwicklung von Reports mit echten Erkenntnissen fließen könnte. Andererseits führen automatisiertes Testing, Orchestrierung, Versionskontrollen und Co. dazu, dass die Qualität und Robustheit von Data-Pipelines bei weit geringerem manuellen Aufwand signifikant erhöht wird.
Als offizieller Partner von dbt helfen wir dir gerne dabei, dass auch du die Vorteile von dbt im Aufbau und der Weiterentwicklung deiner Dateninfrastruktur nutzen kannst: angefangen bei der Toolkonfiguration im Tech-Stack über die best-practice Modellierung der undurchsichtigsten Rohdaten bis zum Quercheck deiner bestehenden dbt-Transformationen.



